

Kas yra robots.txt
Robots.txt – tai nedidelis tekstinis failas, dedamas į svetainės šakninį katalogą, kuriame pateikiami nurodymai paieškos sistemų robotams arba naršyklėms, kuriuos svetainės puslapius ar skirsnius reikia naršyti, o kurių – ne. Tai labai svarbus įrankis, kuriuo naudodamiesi svetainių savininkai ir SEO specialistai gali kontroliuoti, kaip paieškos sistemos pasiekia ir indeksuoja jų svetainių turinį.
Turinio lentelė
Robots.txt istorija
Robots.txt pirmą kartą 1994 m. pristatė Martijnas Kosteris kaip būdą svetainių savininkams bendrauti su žiniatinklio robotais ir neleisti jiems pasiekti tam tikrų svetainių dalių. Nuo to laiko robots.txt vystėsi, buvo sukurti įvairūs paieškų tinkle interneto standartai, apibrėžiantys robots.txt failo kūrimo sintaksę ir taisykles.
Robots.txt failo paskirtis
Pagrindinė robots.txt paskirtis – pateikti nurodymus paieškų sistemų robotams, kurias svetainės dalis paieškos sistemos turėtų nuskaityti ir indeksuoti, o kurias blokuoti. Tai padeda svetainių savininkams neleisti paieškos sistemoms indeksuoti neskelbtinos informacijos, pasikartojančio turinio ar nereikšmingų puslapių, kurie gali turėti įtakos svetainės pozicijoms paieškos sistemose.

Kas yra „crawler” „botai”
Crawleriai, dar vadinama botais arba paieškų sistemų vorais, yra programinė įranga, kuri automatiškai keliauja po internetą ir sistemingai skenuoja svetaines, kad surinktų informaciją indeksavimo tikslais. Naršyklės dažniausiai naudojamos paieškos sistemose, pavyzdžiui, „Google”, „Bing” ir „Yahoo”, siekiant aptikti ir indeksuoti tinklalapius, kad juos būtų galima rasti ir rodyti paieškos rezultatuose. Naršyklės seka nuorodas iš vieno puslapio į kitą ir renka tokius duomenis kaip URL, puslapių pavadinimai, meta žymos, turinys ir kt. Šie robotai vaidina svarbų vaidmenį paieškos sistemoms ieškant, indeksuojant ir reitinguojant tinklalapius, o tai galiausiai daro įtaką tinklalapių matomumui ir reitingui paieškos rezultatų puslapiuose (SERP).
Robots.txt failo sintaksė ir taisyklės
Robots.txt sintaksė yra paprasta ir susideda iš dviejų pagrindinių komponentų: Vartotojo agentas (User-agent) ir uždrausti (Disallow). Vartotojo agentas (User-agent) – nurodo paieškos sistemos roboto arba naršyklės pavadinimą, o „Disallow” nurodo katalogus arba failus, kurių tas konkretus žiniatinklio robotas neturėtų naršyti arba indeksuoti. Štai robots.txt failo pavyzdys:
User-agent: *
Disallow: /wp-admin/
Allow: /blog/iraso-nuoroda/Pirmiau pateiktame pavyzdyje vartotojo agentas (User-agent) „*” nurodo, kad šie nurodymai taikomi visiems paieškų sistemų robotams, o „Disallow” „/wp-admin/” nurodo, kad „wp-admin” katalogas neturėtų būti naršomas ar indeksuojamas jokių paieškos sistemų robotų.
Toliau pateikiamos kelios taisyklės, kurių reikėtų nepamiršti kuriant robots.txt failą:
- Visada naudokite mažąsias raides nuorodose User-agent ir Disallow.
- Naudokite priekinius brūkšnelius „/” katalogams arba failams nurodyti.
- Naudokite simbolį „*”, kad nurodymus taikytumėte visiems žiniatinklio robotams.
- Norėdami nurodyti nurodymus skirtingiems žiniatinklio robotams, naudokite kelias User-agent eilutes.
Naudotojo agentai (User-agents)
Kiekviena paieškos sistema save identifikuoja skirtingu naudotojo agentu. Kiekvienai iš jų robots.txt faile galite nustatyti pasirinktinius nurodymus. Naudotojų agentų yra šimtai, tačiau čia pateikiami keli naudingi SEO:
- Google: Googlebot
- Google paveiksliuku: Googlebot-Image
- Bing: Bingbot
- Yahoo: Slurp
- Baidu: Baiduspider
- DuckDuckGo: DuckDuckBot
- Ahrefs (SEO įrankis): AhrefsBot
Svetainės žemėlapis robots.txt faile
Šią nuorodą naudokite norėdami nurodyti svetainės žemėlapio (-ių) vietą paieškos sistemoms. Jei nesate susipažinę su svetainių žemėlapiais, į juos paprastai įtraukiami puslapiai, kuriuos norite, kad paieškos sistemos peržiūrėtų ir indeksuotų.
Štai robots.txt failo, kuriame naudojama svetainės žemėlapio nuoroda, pavyzdys:
Sitemap: http://simpleseo.lt/sitemap.xml
Disallow: /wp-admin/
Allow: /blog/iraso-nuoroda/Kiek svarbu įtraukti svetainės žemėlapį (-ius) į robots.txt failą? Jei jau pateikėte per „Search Console”, „Google” tai šiek tiek nereikalinga. Tačiau kitoms paieškos sistemoms, pavyzdžiui, „Bing”, jis nurodo, kur rasti jūsų svetainės žemėlapį, todėl tai vis dar yra gera praktika.
Kodėl tinklalapyje reikia naudoti robots.txt?
Naudodami robots.txt galite geriau kontroliuoti paieškos sistemų naršymą ir indeksavimą, pagerinti SEO našumą, padidinti svetainės saugumą ir privatumą bei efektyviai valdyti naršymo biudžetą.
Ar galiu naudoti robots.txt, kad užblokuočiau visų interneto robotų prieigą prie savo svetainės?
Taip, galite naudoti robots.txt, kad užblokuotumėte visų interneto robotų prieigą prie savo svetainės naudodami šią nuorodą:
User-agent: *
Disallow: /
Tačiau ją reikėtų naudoti atsargiai, nes ji neleis visiems žiniatinklio robotams, įskaitant teisėtus robotus, pvz., paieškų sistemų robotus, naršyti ir indeksuoti jūsų svetainės.
Kaip dažnai turėčiau atnaujinti robots.txt failą?
Rekomenduojama reguliariai peržiūrėti ir atnaujinti robots.txt failą, ypač kai keičiate svetainės turinį ar struktūrą. Taip užtikrinsite, kad paieškų sistemų robotams pateikiami nurodymai būtų tikslūs ir tinkami.
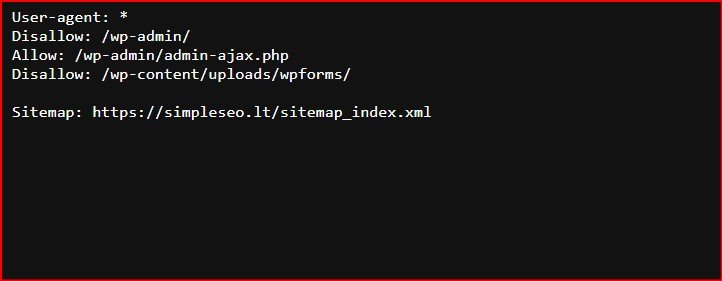
Kaip rasti robots.txt failą
Jei savo svetainėje jau turite robots.txt failą, jis bus pasiekiamas adresu domain.com/robots.txt. Naršyklėje pereikite prie šio URL adreso. Jei matote kažką panašaus į tai, vadinasi, turite robots.txt failą:

Išvada
Apibendrinant, robots.txt yra galingas veiksnys, kuriuo naudodamiesi svetainių savininkai gali kontroliuoti paieškų sistemų robotų naršymo ir indeksavimo elgseną savo svetainėse. Jis gali padėti išvengti turinio dubliavimo, apsaugoti neskelbtiną informaciją, valdyti naršymo biudžetą ir pagerinti SEO našumą. Tačiau juo reikia naudotis atsargiai, kad būtų išvengta netinkamo konfigūravimo rizikos ir užtikrinta, kad jis atitiktų svetainės SEO strategiją ir tikslus.
Šaltinis: https://ahrefs.com/blog/robots-txt/





